Concepts in Machine Learning Class 1: Introduction to Machine Learning
Objectives
Welcome to Concepts in Machine Learning from fredhutch.io! This course is designed for researchers who are interested in machine learning, and assumes no prior programming or statistics experience. There are no prerequisites for this course.
This course will introduce you to machine learning and focus specifically on supervised and unsupervised machine learning methods. Further, researchers who complete this course should have an understanding of how machine learning can be applied in biology research. The goal of this course is to provide some conceptual background for our Intermediate R and Python courses in Machine Learning.
By the end of this course you should be able to:
- Identify how machine learning can be applied in biology research.
- Apply the concepts of exploratory data analysis, experimental design, and ethics in machine learning.
- Recognize the four main paradigms of machine learning as supervised, unsupervised, semi-supervised, and reinforcement learning.
- Differentiate between common approaches and methods for supervised and unsupervised machine learning.
- Recognize and have a basic understanding of common approaches to supervised (regression, classification) and unsupervised (clustering, dimensionality reduction) machine learning.
Today’s lecture will focus on providing a broad introduction and structure to many of the concepts we will cover throughout the rest of this course.
By the end of this class you should be able to:
- Define and understand the limitations of machine learning.
- Understand basic terminology like algorithm, inputs, outputs, supervised, unsupervised.
- Differentiate between unsupervised and supervised machine learning methods.
What isn’t machine learning?
Buzzwords like ‘machine learning’, ‘deep learning’, and ‘artificial intelligence’ get thrown around quite a bit these days. Sometimes they seemed to be used as synonyms, other times as distinct entities. Because of this, it can be hard to determine exactly what these terms mean to the layperson. So let’s start with what machine learning isn’t.
Like any new technique that gains traction and buzz in the field, suddenly everyone wants to jump on the machine learning bandwagon. However, machine learning isn’t a shiny, new toy to be showed off or assessory to be casually added to an analysis. As with all statistical methods, it can be powerful when applied correctly or extremely misleading and outright wrong when applied incorrectly.



Machine learning is NOT:
- Magic
- A secret sauce
- Seasoning to be sprinkled liberally over a mundane application
- A substitute for a good understanding of your problem
What is machine learning?
Recent advances in compute power, cloud technologies, data collection and data generation have thrust machine learning into the mainstream. Increasingly machine learning is looked to as a tool to solve big complex problems like cancer. Often though the term machine learning is used as a sort of black box, but what actually is machine learning?
Let’s orient ourselves to the terms mentioned above that you may be familiar with in popular culture to get a sense of how things fit together.
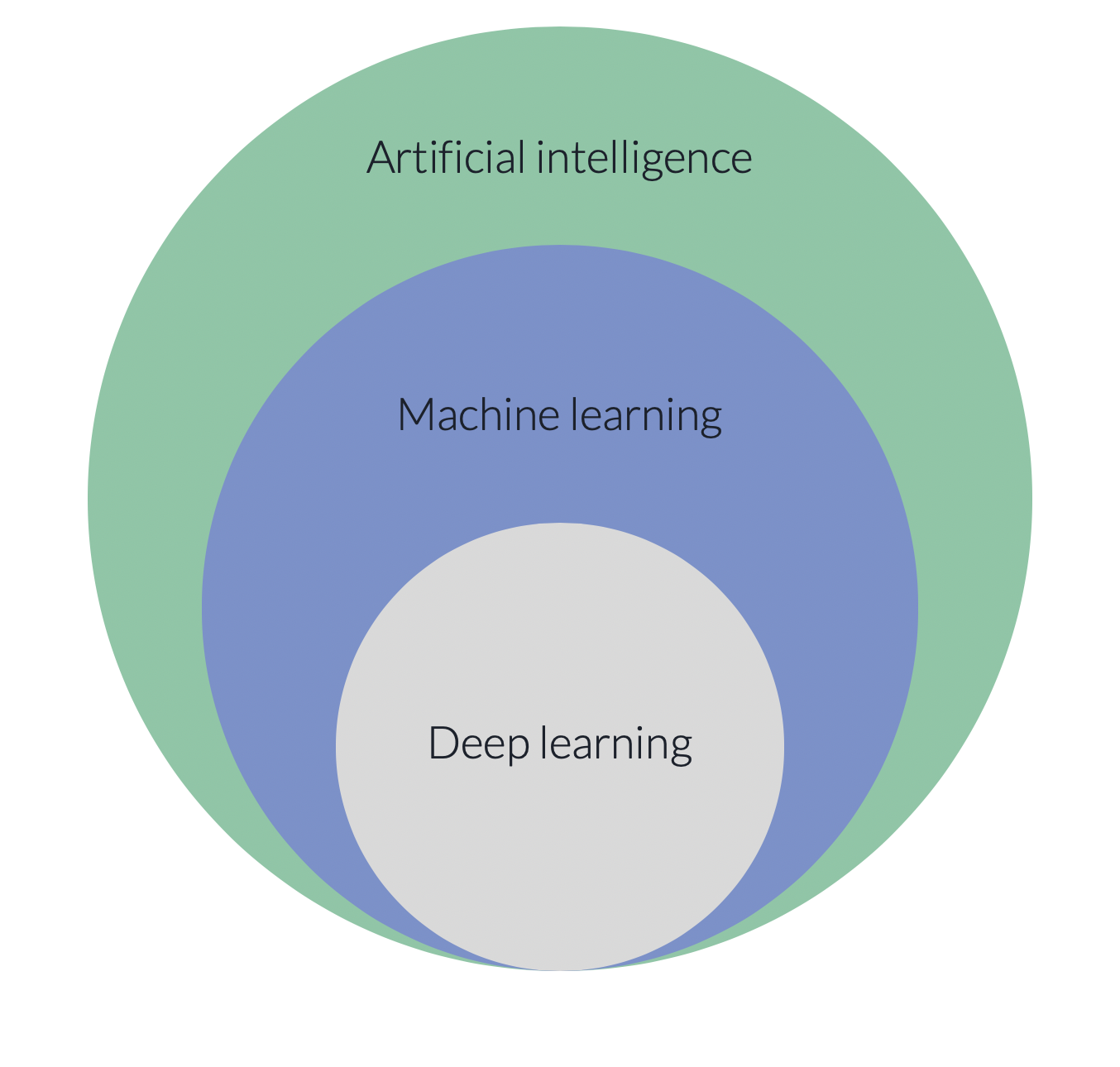
- Artificial intelligence (AI) is a term that embodies anything that enables computers to act more like humans. This is a field of knowledge like ‘chemistry’ or ‘physics’.
- Machine learning is a field of study within AI, similar to how molecular biology is a specific focus in biology. The focus of this field is on the extraction of patterns from large datasets.
- Deep learning is an example of a collection of similar machine learning methods. Other examples of collections of machine learning methods include, decision trees and regressions.
Machine learning defined
Let’s look at how machine learning is defined.
Wikipedia: Machine learning (ML) is the study of computer algorithms that improve automatically through experience. It is seen as a subset of artificial intelligence. Machine learning algorithms build a mathematical model based on sample data, known as “training data”, in order to make predictions or decisions without being explicitly programmed to do so.
Merriam Webster: the process by which a computer is able to improve its own performance (as in analyzing image files) by continuously incorporating new data into an existing statistical model.
Nature Genetics Review: The field of machine learning includes the development and application of computer algorithms that improve with experience.
While these definitions vary slightly there are a few common themes to pull out:
- Machine learning is a kind of algorithm.
- Algorithm - A finite sequence of well-defined, computer-implementable instructions, typically to solve a class of problems or to perform a computation
- Essentially it is a protocol for a computer
- Machine learning incorporates data into a statistical model.
- Machine learning improves with experience without human intervention.
Machine learning as code
Machine learning principles are applied to data using computer code and the computational methods involve specific characteristics.
- Most programming isn’t built to learn - it’s procedural
- This is where a programmer builds out a set of rules. This set of rules is called an algorithm. This ruleset remains static unless the coder intervenes and specifies more rules.
- In machine learning the algorithm is also designed and coded by a human. However, this kind of algorithm is able to learn from the data about specific parameters that will shape a statistical model for making predictions and inferences. The coder doesn’t necessarily know or control these parameters - the machine does.
Machine learning is an algorithm (or set of rules) that self adjusts based on the large datasets that it is given
Challenge - Writing a protocol
This challenge aims to illustrate the difference between writing a straightforward procedural algorithm versus writing a predictive algorithm.
- Write an algorithm/protocol/ruleset for making a PBJ sandwich.
- Write an algorithm/protocol/ruleset for determining if an email is spam.
click here to go to solutions page
When to use machine learning
Just like any other statistical method there are specific situations where applying machine learning is appropriate.
You cannot code the rules:
- Tasks that cannot be solved using a simple, rule-based solution.
- When rules depend on too many factors and many of these rules overlap or need to be tuned very finely, it soon becomes difficult for a human to accurately code the rules. You can use ML to effectively solve this problem.
- This is true for drawing conclusions about highly dimensional data.
You cannot scale:
- You might be able to manually recognize a few hundred emails and decide whether they are spam or not. However, this task becomes tedious for millions of emails. ML solutions are effective at handling large-scale problems.
Just as important as the algorithm itself is a solid understanding of experimental design, domain expertise in the problem area youre trying to solve, and an understanding of data governance and ethics.
How is machine learning applied?
Machine learning applications are all around us! Every time Spotify serves up a customized playlist or radio station based on the music that you like, Facebook loads your newsfeed, or you interact with a voice assitant like Siri, you are interacting with machine learning algorithms.
Every-day applications:
- Search engines
- Recommendation systems (Yelp, Netflix, Spotify)
- Voice assistants
- Social media feeds
- Text prediction
Biomedical research can benefit from utilizing machine learning

In the past data generation had been a bottleneck in biology research but this is no longer true! Biology research is generating huge amounts of messy and complex data! Now the challenge is figuring out how to integrate datasets and find the underlying patterns to make sense of the massive amounts of data we currently have.
Machine learning is an appropriate approach for many biological questions:
- You cannot code the rules
- Biological systems are incredibly complex with many inputs leading to complex phenotypes.
- Example: if you want to determine whether or not a patient is likely to get cancer we’d need to take many datasets into account (demographic data, health/nutrition data, family history, genetic data, etc). We cannot determine and code the rules for a computer to calculate if a person is likely to get cancer or not.
- You cannot scale
- Our human brains cannot make sense of these huge integrated datasets or even just one of them.
- Example: a human looking at a series of bases would take years to make sense of the human genome. A computer can find patterns in our genome with relative ease.
Machine learning techniques are becoming increasingly important to biological research.
Researchers are developing algorithms that use machine learning to classify histopathological images, visualize and find clusters within single cell datasets, and much more.
Biology specific applications:
- Prediction of protein secondary structure based on RNA-sequence.
- Classification of histopathological images of breast tissue to identify malignant tumors.
- Using gene expression data to classify patients into different clinical groups.
Machine learning work that is happening here at Fred Hutch:
- Gottardo lab - automatic gating for flow cytometry data.
- Emily Silgard’s data science group - natural language processing to extract information from unstructured electronic medical records notes.
- The Data Visualization Center - single-cell visualization and clustering of RNA-sequencing data to find rare subtypes of cells that emerge in the mouse embryo.
Anatomy of a machine learning problem
The purpose of using machine learning is generally to use data make an inference or prediction. To do this, these algorithms access large datasets with many variables. Datasets rarely, if ever, will capture all of the complex underlying systems that result in the reality that we see in the world. Datasets merely capture variables that we think are related to the system that we are trying to uncover and that we can adequately measure and track.
Here’s a peek at a portion of a training dataset for predicting whether or not a patient might be diagnosed with cardiovascular disease. The full dataset contains 425,195 rows.
| patient_Id | age | htn | treat | smoking | race | t2d | gender | numAge | bmi | tchol | sbp | cvd |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HHUID00076230 | 20-40 | Y | Y | N | Asian/PI | N | M | 29 | 23 | 189 | 170 | N |
| HHUID00547835 | 70-90 | N | Y | N | White | Y | M | 72 | 35 | 178 | 118 | N |
You might have noticed that this fairly small collection of features will not capture all of the complexities that lead to a diagnosis of cardiovascular disease, but it might capture enough variability to build a model and make accurate predictions. Only experimentation will show if this dataset is capable of creating an accurate and generalizable model.
You’ll notice that this dataset consists of variables that are very easy for someone to measure.
Variables that are difficult to measure that might be related to cardiovascular disease:
- Stress
- Dietary habits
- Sleep habits
It’s important to think critically about what features we want to include in our datasets, what features might be missing, and identify features that may introduce biases into the analysis. We will discuss exploratory data analysis and ethics as key pieces of the machine learning process in class 4 of this course.
Note!
The dataset above is from the package
cvdRiskData. you can find more information here. We will be using this dataset as an example throughout this course.
Reality/truth: A persons health history, location, occupation, diet, exercise habits, and stress levels, among many other things will play into if someone gets diagnosed with cardiovascular disease.
Feature: A variable that we are capturing in our dataset. Column headers describe each feature in a dataset.
Dataset: A collection of features. When creating the dataset that will be used to make our predictions we will never capture the whole truth. We will capture as much of the truth as we can by collecting data on various features that we believe are related to the problem we are trying to solve. Many underlying factors that lead to the cardiovascular disease may be unknown or we might not be able to measure them to capture them in our dataset.
Inputs: Features that we have collected and will use to make our prediction. Sometimes we will have datasets that have features that will not be included in downstream analysis. For example, in this dataset our inputs would be all of the columns except patient_Id and cvd. We would likely remove pateint_Id because a random identifier won’t have any predictive power and cvd would not be included as an input since it is the target we are trying to predict.
Output: The variable that we are trying to predict. In this case cvd.
Challenge - Building a dataset
The purpose of this challenge is to get students to think critically about identifying features that might be useful in building a model including the limitations that these features might introduce into the model.
- If we are trying to predict whether or not an animal is a cat or a dog what features might we collect?
- Are there any outlier cases you can think of that might confuse your model based on the features you’ve chosen?
click here to go to solutions page
How do machine learning applications work?
There are different types of machine learning and each have their own specific applications and requirements.
Four major paradigms in machine learning:
- Supervised: The machine learning task of learning a function that maps an input to an output based on example input-output pairs. It infers a function from labeled training data consisting of a set of training examples.
- Unsupervised: A type of machine learning that looks for previously undetected patterns in a data set with no pre-existing labels and with a minimum of human supervision.
- Semi-supervised: An approach to machine learning that combines a small amount of labeled data with a large amount of unlabeled data during training. Semi-supervised learning falls between unsupervised learning (with no labeled training data) and supervised learning (with only labeled training data).
- Reinforcement learning: An approach to machine learning concerned with how software algorithms ought to take actions in an environment in order to maximize the some reward.
The focus of this course will be on supervised and unsupervised learning only, but it’s good to be aware that these are not the only types of machine learning. While increasingly complex machine learning algorithms are highlighted on TV and in the news, it’s important to remember that the most commonly implemented form of machine learning is the simplest - supervised machine learning.
An overview of supervised learning
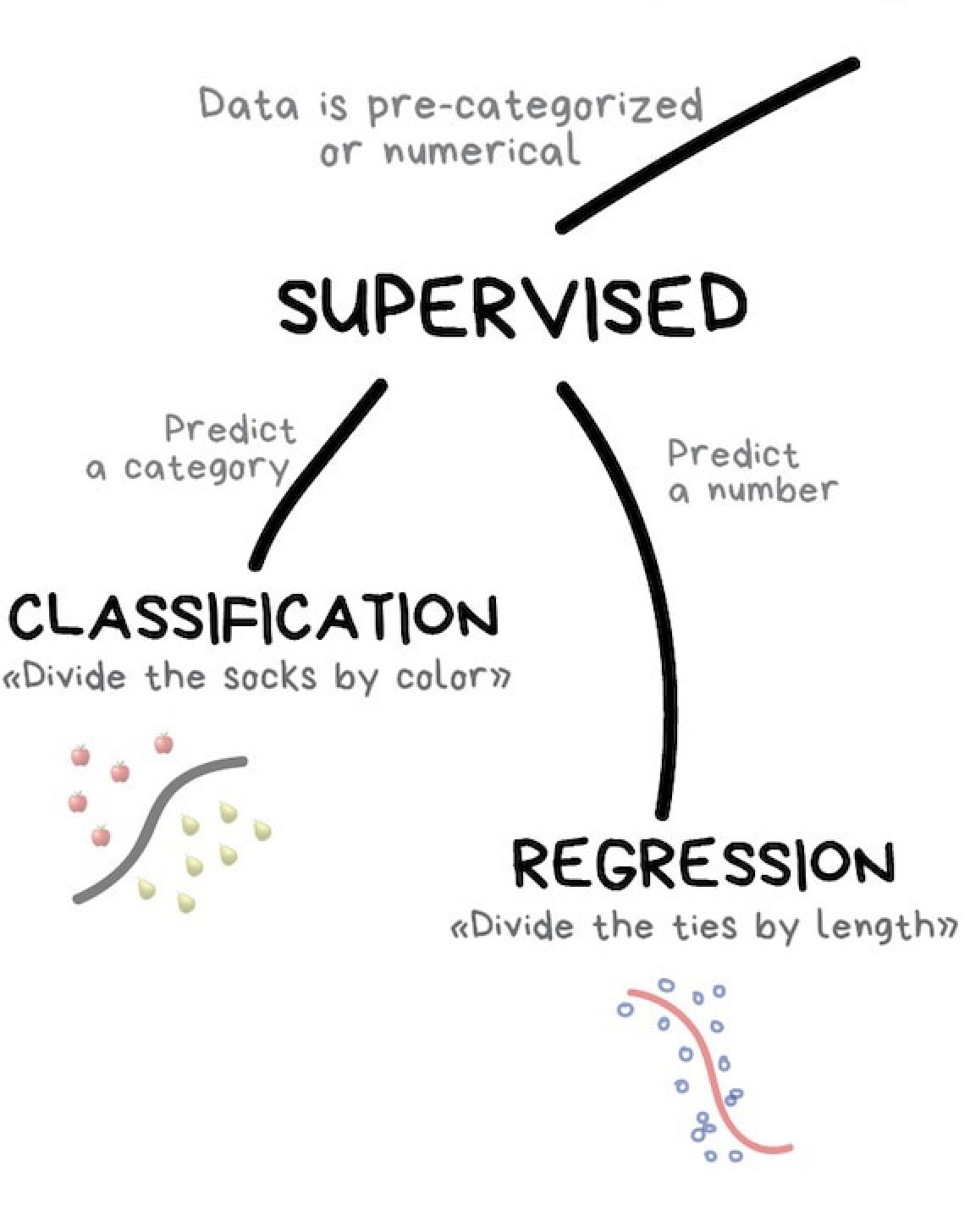
The goal of supervised machine learning is to fit a model that relates response variables to predictors and can accurately predict the response for future observations of predictor variables. We will cover supervised learning more in depth in class 2 of this series.
Supervised learning is one of the most commonly used forms of machine learning and it’s generally easier to implement and interpret than unsupervised learning alogrithms.
A hallmark of supervised learning algorithms is that they work in two steps: training and testing. This requires training the algorithm on example datasets with inputs that are annotated (or labled) with the correct response. Once training is complete the algorithm will be tested on a seperate labled dataset and it’s performance is evaluated.
Ideally an the algorithm will be specific enough to accurately predict the response variable, but generalizable so that it works with new datasets.
There are two subclasses of supervised learning:
- Regression: predicting a numeric
- Classification: predicting a category
An overview of unsupervised learning
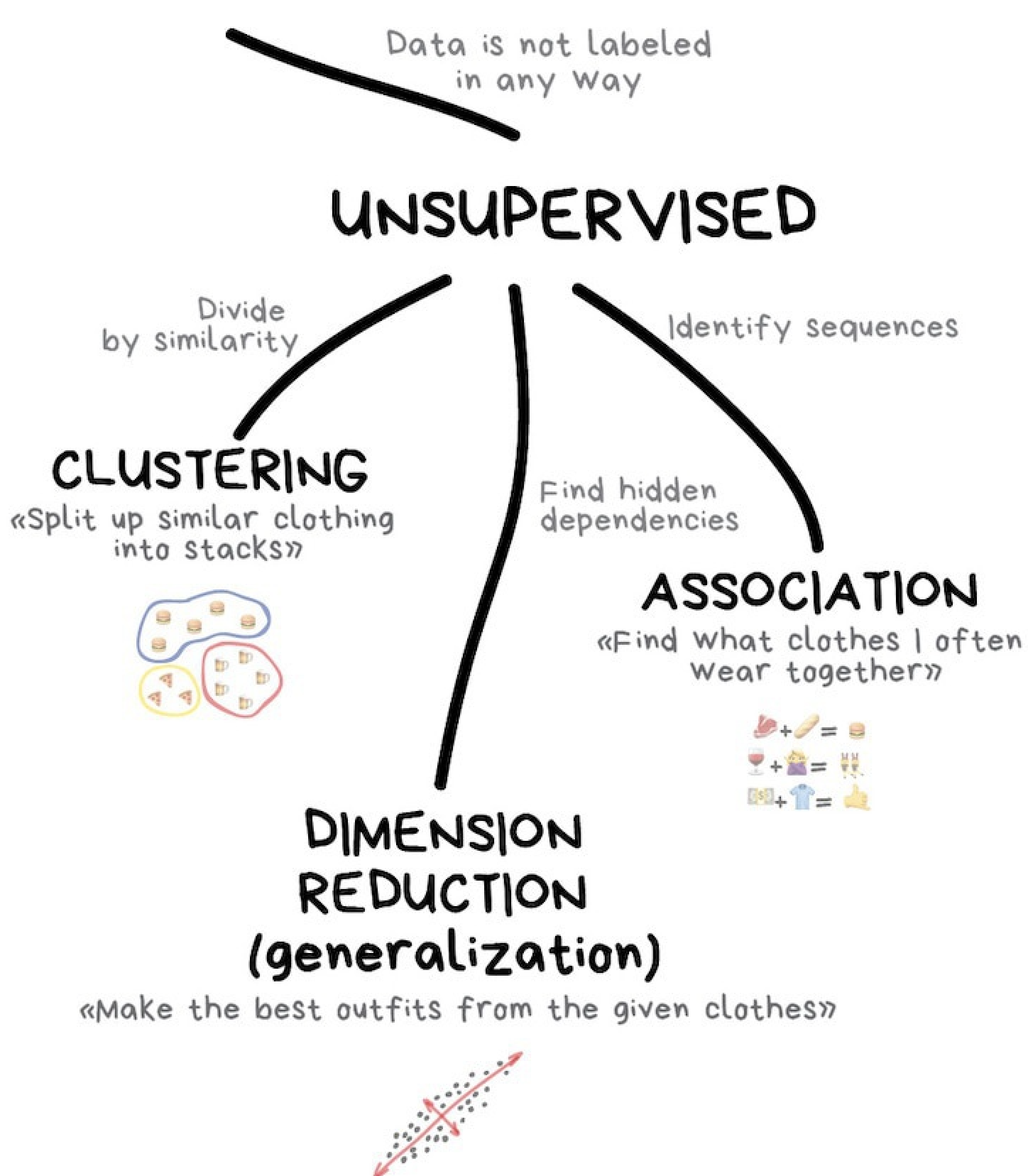
The goal of unsupervised learning is to explore a dataset and discover similarities between objects. These similarities define groups of objects (AKA clusters). Unlike with supervised learning, these algorithms do not require labled example datasets to train on. Instead the algorithm works by grouping together objects based on similarities in can find in the dataset. We will dive deeper into unsupervised learning in class 3 of this series.
Unsupervised learning results can be harder to interpret than supervised machine learning. This is a direct result of the fact that these algorithms do not take in labled data. Since the data is unlabeled we are unable to “tell” the algorithm what output we are looking for.
Further, because there is no need for labeled data, unsupervised algorithms only have one step: fitting. Unsupervised machine learning algorithms have underlying models that they use to determine how similar objects are and create groupings. Fitting is the stage where the algorithm runs the data through the model.
There are two subclasses of unsupervised machine learning:
- Unsupervised transformations: Create a new representation of a complex dataset that is easier to understand than the original.
- Clustering: Partition data into distinct groups of similar objects.
Challenge!
Determine whether the following problem statements are supervised or unsupervised machine learning.
- Based on genetic data which species of birds are more closely related?
- What demographic sub groups exist of people that like Horror movies?
- Can we determine if an email is spam based on the text in the email?
- Given a database of images can we pull out all the distinct faces?
click here to go to solutions page
Wrapping up
Today, we briefly explored some of the main ideas we will be covering throughout this course including exploratory data anlysis, dataset collection, and supervised and unsupervised learning concepts and methods. For further reading on these topics check out the optional materials below.
Next class we will dive deeper into supervised learning. We will discuss more about data collection and how it relates to supervised learning, examine classifcation and regression methods, practice identifying and writing problem statements, and discuss common issues with supervised machine learning like over-fitting.